
I wanted to jot down some of my experiences with teaching error propagation. Right off the bat I should note that I have been greatly influenced by this document by John Denker in response to questions about this topic on the PHYS-L listserv. I especially like his rant against significant figures in that document, but I’ll let that go for now.
I’d like to talk about how I encourage the high school teachers in my licensure program to do and teach error propagation. I don’t do the calculus method because, um, it requires calculus and students get bogged down in that instead of the important stuff (things like 

Before I forget, here’s the calculus method. Assume you’ve measured a, b, and c with their associated errors 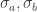


You can see why it’s a hassle, what with the partial derivatives and all the terms to keep track of. One (of many) nice things about it is how you can quickly see which variable you should spend money on.
Montecarlo method
The Montecarlo method uses a computer to do many simulations of the experiment, where the variables are all randomly selected to be close to the best measurement you make. Specifically, you create several normally distributed (assuming that’s the distribution of your data – a common case) random numbers that resemble the original data set. You then let the computer calculate the formula of interest several times over and then take the average and standard deviation of those to determine the best estimate of the function and the error on the function.
I encourage students to do this with spreadsheets. Each column is a variable measured in class. Then you add a column for any calculations that you care to do with that data. You use a command to generate the random numbers, stretch the formulas down a few 100 or 1000 rows, and then use the typical Average and Stdev commands on the columns you care about.
For me, the biggest difficulty was finding the command in Excel and Google Docs that does the random number generation. Rand() doesn’t do the trick because that’s a uniformly distributed random number between 0 and 1, as opposed to a normally distributed random number around a mean with a given standard deviation.
norminv()
Well, I finally found it. The norminv( ) function does the trick nicely in both Excel and Google Docs. If you want a random number normally distributed around, say, 5.6, with a standard deviation of 1.2, you do this:
norminv(rand(), 5.6, 1.2)
Go try it, it’s fun! Stretch it down a few rows and you’ll get a different answer on every row.
So each column has that going on for every variable measured in the experiment. You make new columns for any calculations. Here’s an example:
[youtube http://www.youtube.com/watch?v=dp60KKhjPY4]It doesn’t take students very long to grasp the concept and I make sure they’re doing it on the fly in their labs all the time. It certainly beats the calculus method in one major point: the complexity of the problem doesn’t affect how hard it is to do in a spreadsheet (assuming you can type your formula into excel or google docs). In the calculus method, the complexity can really be daunting for some students.
How far is enough to stretch?
I used Mathematica to test the notion of how far to go. It’s faster to do the random number generation (use the command RandomReal[NormalDistribution[mean, stdev]]) and I can make histograms faster as well. Here are plots of the histogram for several random numbers with a mean of 5.2 and a standard deviation of 1.3. The number of “rows” goes from 10 up to 100,000 by factors of 10:

Histograms of normally distributed random numbers
You can see the signature normal distribution towards the bottom, but in fact, even for just 100 points, the mean and standard deviation are perfectly acceptable. In Excel it’s pretty easy to drag down 1000 rows, but after 100 you don’t get results that are that different. I certainly encourage my students to play around with how many they need to use.
This works well for me, but I never feel like the students get to the point where they realize just how important/powerful error propagation is. How do you teach/do it?

This is great; I’ve been thinking about how to avoid the “calculus method” of propagating error in intro mechanics. One question. Do your students write lab reports? If so, how do you have them describe this method, or explain where their uncertainty estimates come from?
In early lab reports, I ask for a representative print-out of the spreadsheet. Once I can tell that they know what they’re doing, I simply ask for the results of the error analysis. Often, in lab, I go around to make sure they’re setting up the spreadsheet correctly. Depending on the setting, I’ll often ask them to submit the spreadsheet in addition to the report.
With my advanced students I have them do this in Mathematica. There you can check the syntax but suppress the 1000’s of outputs. That makes it much easier for them to put it in lab reports.
Andy,
As always, this is great. You’ve got me thinking that I’m going to work to get back to doing more uncertainty analysis (Mark and I used to do a ton, but the kids hated it and didn’t see the point). We avoided sig figs, but taught a lot about how you combine various measurement uncertainties to get the uncertainty of a calculated quantity. But your method shows we could actually have students simulate thousands of measurements and figure out the rules for themselves.
The two things I think help students to see how important this stuff is are: 1. giving them examples of the incredible amount of work and cost involved in reducing measurement uncertainty. I often show them the catalog page describing a few different balances, like this, this, and this.. They see that you can’t have a “perfect” measurement, and even as you try to reduce the uncertainty of a measurement you also have make tradeoffs—A $22,000 balance with a capacity of 2.1 g? Seriously?
The second thing I think is important is for them to see an example of where reduced uncertainty has made a difference in science. If you really measured the length of the table to all those decimals your calculator tells you, you should win a Nobel prize. Why, because your new measurement technique is also going to allow us to measure the the separation between atoms with unprecedented accuracy.
So I’d love to think of a short, manageable experiment we could do in class, where doing it one way (with crude tools) would leave us unable to make any conclusions. However, increasing the precision of our measurements with better tools, allows us to achieve a new scientific insight, and we would do all of the analysis using some sort of spreadsheet simulating the uncertainty of our measurements.
I love the money approach to getting them to see the value, John. I’ve been thinking of giving students a fake budget and having them figure out the most cost-efficient way to improve a measurement, especially one with lots of different pieces of data that need to be collected with lots of different instruments. I really like the idea of just showing them the catalog prices, that’s cool.
As far as an experiment is concerned, having something in the denominator of an expression is really interesting. Simply a speed measurement with a crappy time error can lead to wild results.
The experiment that really opened my eyes was the minimum deviation experiment to find the index of refraction of a prism. With decent equipment you can find the angle of minimum deviation quite accurately, leading to very accurate measurements of the index of refraction.
Now we’re cooking—I could imagine a sort of lab where you have to play the role of cop—and determine whether or not someone what speeding. I’m thinking you could set up some sort of scale model in class using perhaps a RC car or something similar (I’d want it to be fast enough to be beyond the simple “measure the speed of the buggy labs”) and then compare a number of different ways of making measurements. Can you send the speeder to jail on the basis of your measurement? What will it take?
My students consistently struggle to truly understand measurement uncertainty and error propagation, and I need to try a different way to present these concepts. I think an activity like this may help. This may also provide an opportunity to compare different measurement tools (e.g., stopwatch vs. photogates). I like John’s speeding car example. i wonder if fresh batteries and a sufficiently short distance would even work with the battery buggies. Or, I often start with the pendulum lab and wonder if that could be expanded to include these techniques. (Although, I was thinking of swapping bouncing balls for the pendulum this year.)
I find that giving the students a “challenge” lab where they can get extra credit for correctly finding an unknown value greatly increases their appreciation for uncertainty and experimental technique. For the past couple years I’ve been doing a lab where students put an unknown mass (made out of washers glued together) on a glider on an air track and try to find the mass through a “sticky” collision with another glider. (One tricky part is that the momentum of the gliders is not conserved due to interaction with the track; I have them estimate this from the results of collisions with equal-mass gliders.) To get extra credit they have to get the true answer to within 5% or 10%. When their results come out to be something like 56 g +- 51 g they start to rethink their procedures.
If I did this, I would probably also have them make histograms of all the simulated distributions and have them include those in their lab reports and discuss along with the stated values for mean and s.d. (Not sure how easy it is to produce a histogram in Excel though.) You could also have them play around with their results by changing the s.d. of the measured values and see how that affects the s.d. of the final result.
I like John’s suggestion about using crude tools. One experiment you can try is to have students estimate the length of a wall by using a protractor and a string.
If D is the distance of student to wall, L is the length of wall, and t is the angle from the perpendicular to the edge of wall, then L = D tan t.
When the D is small (the string is short), most of their angles will be close to 90. I’m thinking 80ish. A +/- 1 degree at that point makes a huge difference. Connect this with behavior of the tangent function near 90 degrees.
When the D is larger (the string in long, I’m thinking similar in length to the wall), their angles may be near 45 (assuming a square room). A +/- 1 degree in measurement error won’t make as big of difference as above.
Put up student estimates for both and compare variability of both distributions.
Repeat again, but with this time with surveying equipment such as a theodolite.
If you want the experiment to more match real life. Instead of measuring length of wall, put a fruit or just a round sticker along the wall and ask the students to determine based on their measurements whether the fruit or sticker is moving away or getting closer to them. Have them measure it once, let them out of the room, move it a few inches closer or farther, and have them come back in and measure it again. Be sure to remove furniture near the fruit or sticker as to remove reference points that students can use to cheat.
Have the students in groups and taking measurements. Shouldn’t take too long.
We have our students using the calculus method by the end of first year, but they have no idea WHY it works so one of my plans for my Advanced Lab this upcoming year was to have an activity that starts with Andy’s spreadsheet monte-carlo method, which is then shown to agree with the calculus method. I want to really focus on the graphical displays of each of the measurements so that the students are thinking in terms of “what happens if I add this normal distribution to this one” or similar for other operations.
Another aspect I was going to bring in was independent vs. dependent quantities in the equation. With this you can look at why you add errors in quadrature in the first case and linearly in the second.
Thanks for sharing that John Denker document. I really don’t check in on the PHYS-L listserv that much these days.
I really like it when you can show the calculus method failing. The Denker article has a couple of examples, though I’ve seen it fail often with trig functions and large standard deviations.
I also like the notion of having them plot the histograms. Seeing those curves is much better than saying a +/- b, especially when they’re not normal (as the result might be when using nonlinear functions).
I feel the same way about student evaluation cumulative results. Our scale goes up to seven and the distribution for the whole school continues to rise all the way to seven. You can calculate the standard deviation in those cases but the visual is much more helpful.
I have in the past drawn histograms on the board and argued that if you add or multiply two gaussian/normal histograms, that the resulting histogram will have a new width which is consistent with the answer that the calculus method gives you. But I like the idea of starting with the montecarlo data since you can turn the tables on them and get them to argue for/against adding percentage errors in quadrature vs. linearly.
This is a great read. I will seriously consider doing it this way, for many reasons.
One of the labs we did at Maryland was having students design a carnival game where a projectile had to land in the cup, but only between 20-40% of the time. They had to take measurements to predict where the ball would land, and use their analysis and error analysis to place the location and choose an appropriately sized ring. With out any trials, they then ran the projectile experiment 20 times. It had to land in the ring at least 4 times, but no more than 8. This was of course, near the end of a course where uncertainty and errors were discussed and were the main focus of the labs. What I don’t like about it, is that it’s far removed from authentic science.
Another lab we had them do was giving them two species of cylinders that rolled down ramps. The cylinders were carefully designed to roll down the ramp in the same amount of time, but with different variance. The secret is that neither is perfectly rigid, so the sloshing around introduces variance. They were given 3 species, and had to determine which was different. The trick is that the variance isn’t huge, so you need to beat down your measurement error in order to distinguish the two, and they aren’t told that the means are the same and the variation is different. Once again, while it’s an interesting lab, it’s sort of gimmicky.
I love that phrase “beat down your measurement error.” It seems a lot like the money argument that John makes above.
Pingback: besthotmodels.com | Blog | How Fast Is a Throw From Center Field?
Pingback: Measurement and Uncertainty Smackdown | Science & Technology
Pingback: Another example of why it is essential we teach physics students computational modeling « Quantum Progress
we manufacture physics lab equipment such as, Electrical Instruments, Heat Laboratory Equipment, Mechanics Laboratory Equipment, Measurement Instruments, Meteorology Earth Science Apparatus, Modern Physics Instruments, Optical Instruments read more
Pingback: Day 16: Monte Carlo & Dorothy and Toto | Wildeboer 180
Another way to avoid calculus is to use the functional approach; it is very amenable for use with a spreadsheet.
Further details in the article Error Propagation: A Functional Approach J. Chem. Educ., 2012, 89 (6), pp 821–822
DOI: 10.1021/ed2004627
Pingback: Data Analysis and Presentation for Beginners | Notes from the Hercules Cluster
Pingback: Lab 3: Measuring Stuff | Introductory Physics Lab